journal · 2017
Cloud-based interactive analytics for terabytes of genomic variants data
Cuiping Pan*, Gregory McInnes*, Nicole Deflaux, Michael Snyder, Jonathan Bingham, Somalee Datta, Philip S. Tsao
Bioinformatics
A scalable cloud-based platform enabling interactive analysis of terabyte-scale genomic variant datasets, demonstrating practical approaches for big data genomics.
Abstract
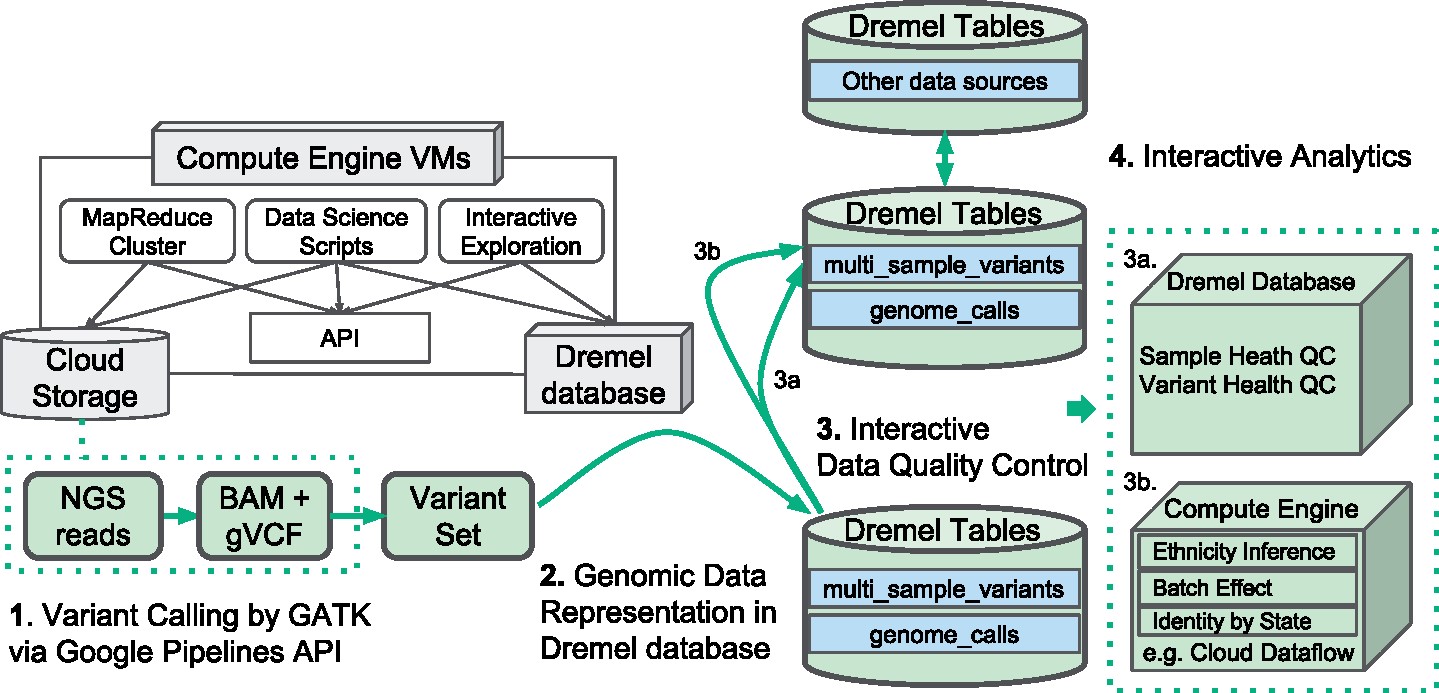
Results: We present interactive analytics using a cloud-based columnar database built on Dremel to perform information compression, comprehensive quality controls, and biological information retrieval in large volumes of genomic data. We demonstrate such Big Data computing paradigms can provide orders of magnitude faster turnaround for common genomic analyses, transforming long-running batch jobs submitted via a Linux shell into questions that can be asked from a web browser in seconds. Using this method, we assessed a study population of 475 deeply sequenced human genomes for genomic call rate, genotype and allele frequency distribution, variant density across the genome, and pharmacogenomic information.
Availability and implementation: Our analysis framework is implemented in Google Cloud Platform and BigQuery. Codes are available at https://github.com/StanfordBioinformatics/mvp_aaa_codelabs.
Big Data, Genomics, 1st Author